WordPress 网站使用 Meilisearch + docs-scraper 全流程部署搜索**
📍 第一步:在宝塔面板上安装 Meilisearch
1.1 安装 Docker
- 打开宝塔后台 → 左侧【软件商店】→ 搜索【Docker管理器】→ 安装。
- 安装完成后,左侧出现【Docker管理器】菜单。
1.2 拉取 Meilisearch 镜像
- 在【Docker管理器】→【镜像管理】→ 搜索 getmeili/meilisearch → 点击拉取。
或使用终端命令:
docker pull getmeili/meilisearch
1.3 创建并运行 Meilisearch 容器
在【Docker管理器】→【容器管理】→【创建容器】,填写:
- 镜像选择:getmeili/meilisearch
- 容器名称:meilisearch
- 端口映射:本地端口 7700 -> 容器端口 7700
- 环境变量添加:MEILI_MASTER_KEY=你的masterKey
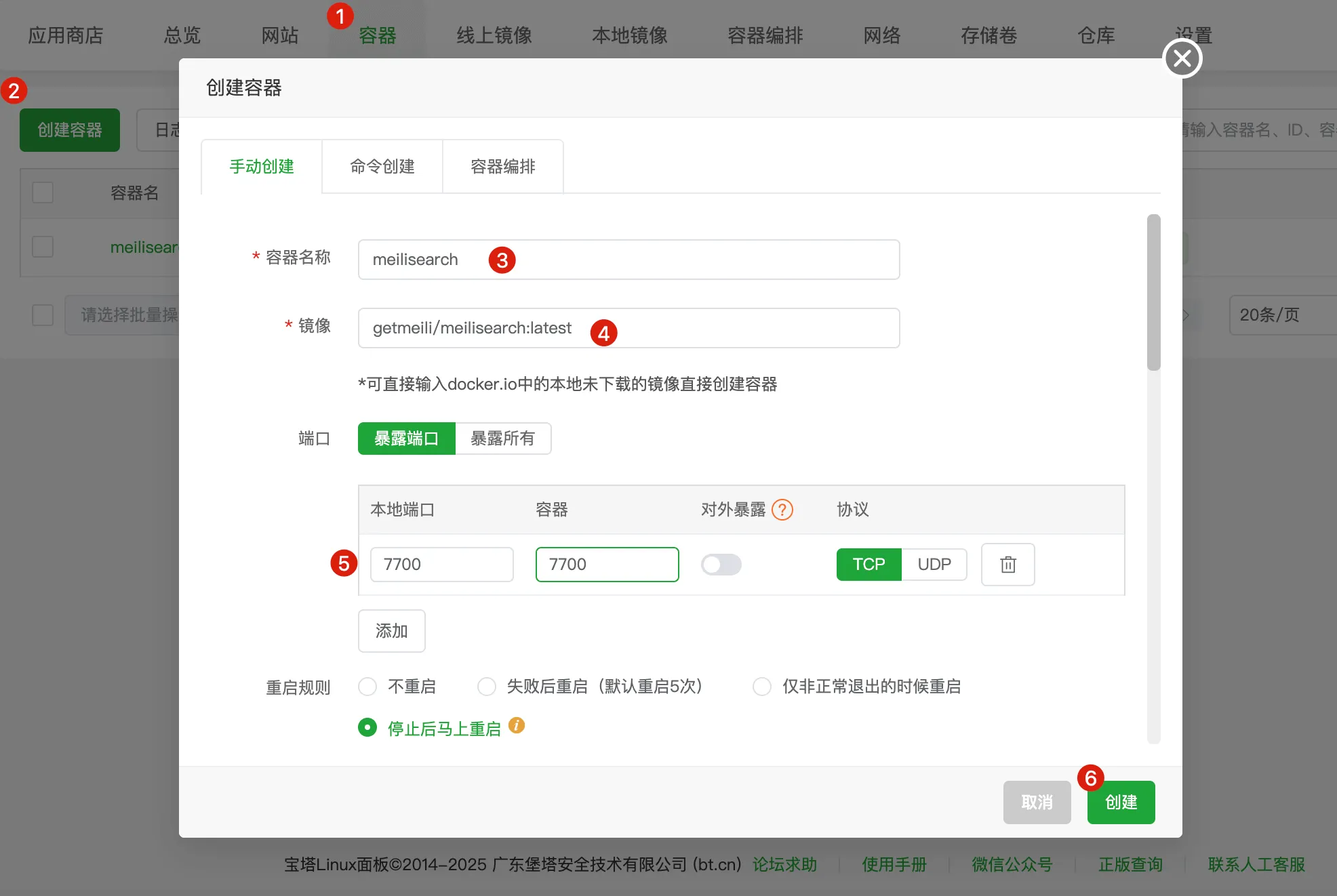
✅ 保存并启动。
📍 第二步:用宝塔面板绑定域名访问 Meilisearch
2.1 域名解析
在域名管理后台添加 A 记录:
- 主机记录:meili
- 记录值:服务器公网 IP
- 类型:A 记录
等待解析生效。
2.2 宝塔添加站点 + 反向代理
- 添加网站,域名填写 meili.XXX.cn,根目录随便。
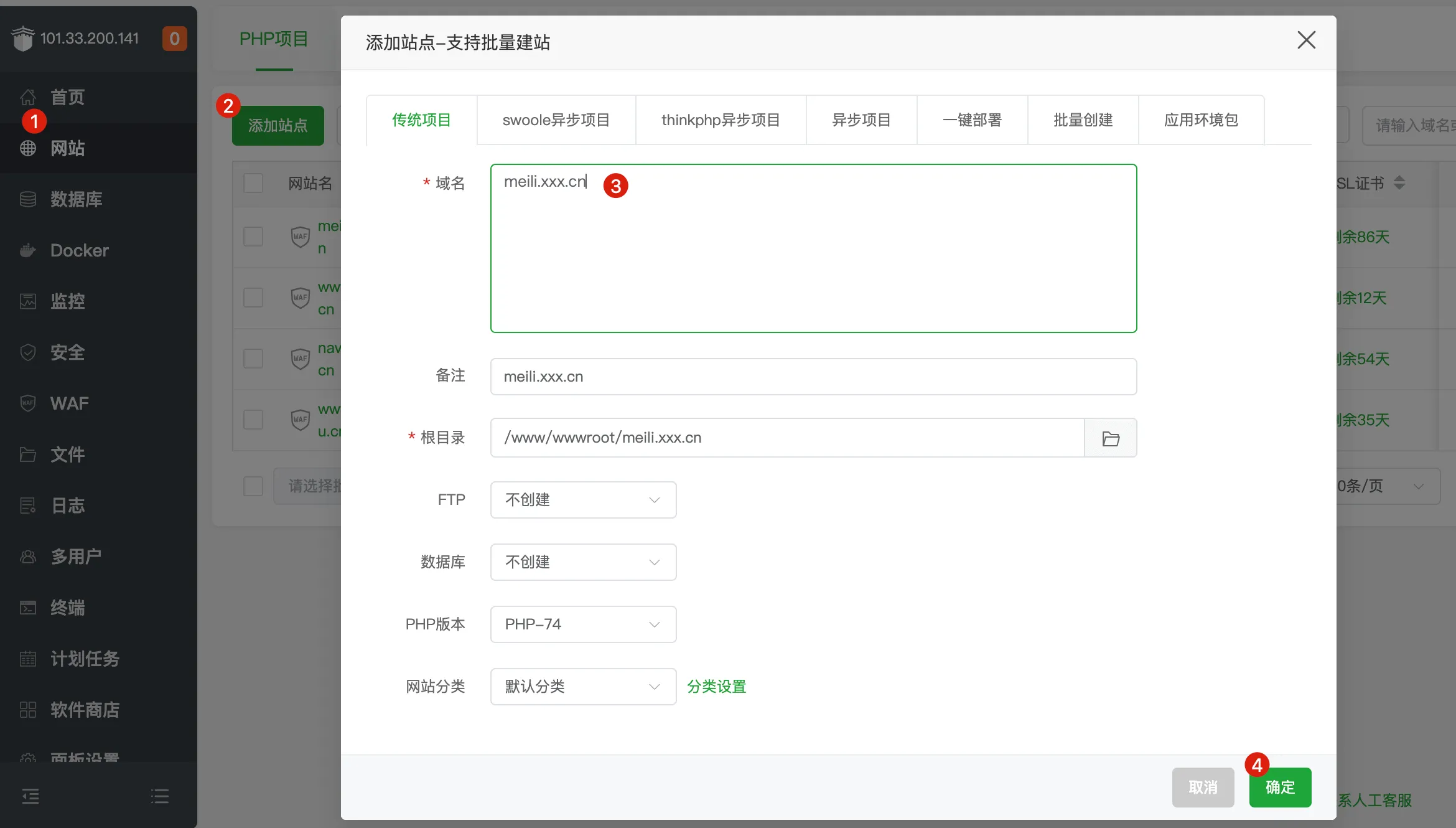
-
设置反向代理:
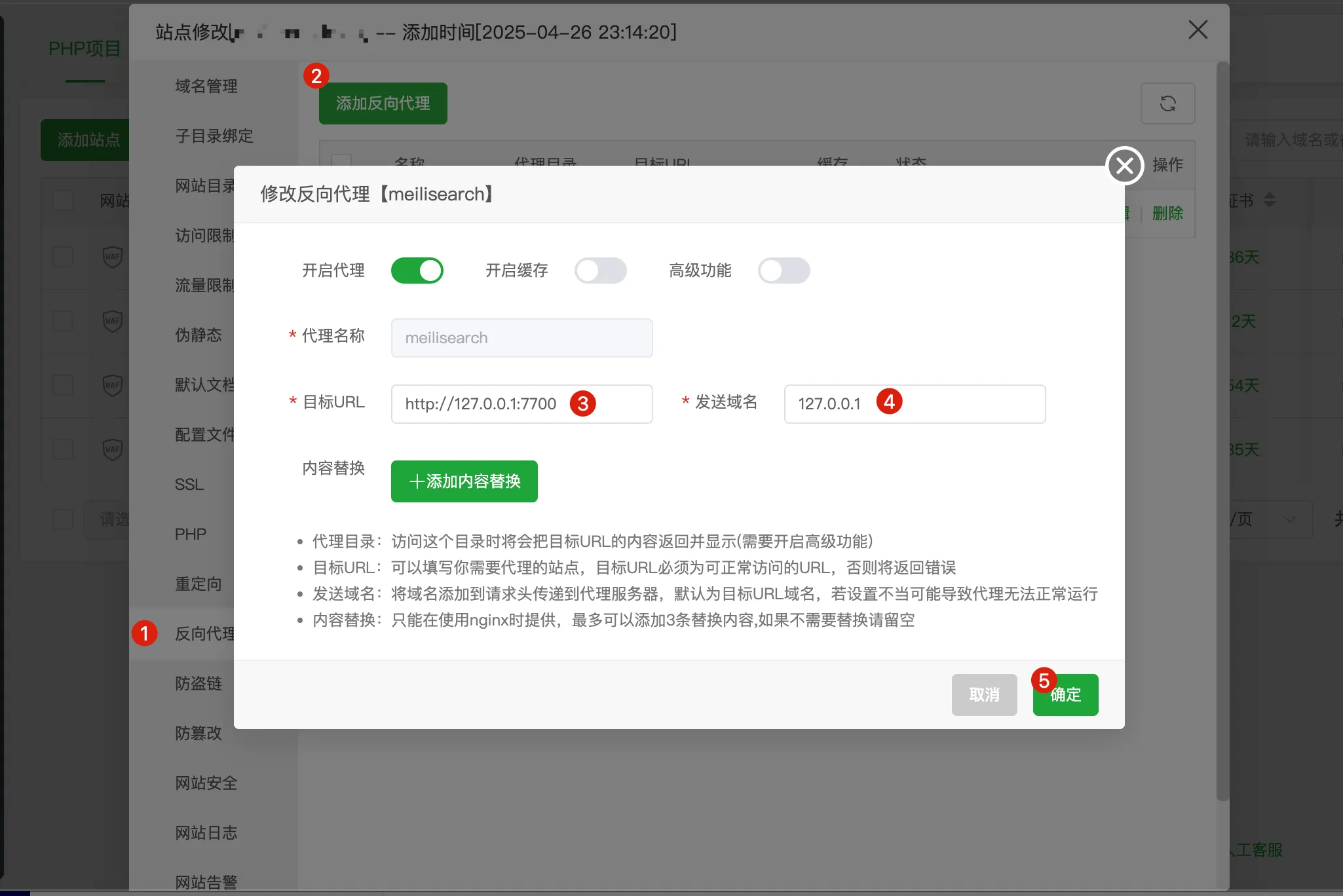
- 目标 URL 填写 http://127.0.0.1:7700
- 启用反向代理
2.3 配置 SSL(HTTPS)
- 在【网站设置】→【SSL】申请 Let’s Encrypt 免费证书。
- 勾选【强制 HTTPS】。
✅ 访问 https:// meili.XXX.cn,可以正常打开 Meilisearch 后台。
📍 第三步:上传官方示例索引 movies.json 到 Meilisearch
3.1 下载 movies.json 示例文件
在服务器终端执行:
wget https://meilisearch.org.cn/movies.json -O /www/movies.json
3.2 上传 movies.json 到 Meilisearch
curl -X POST 'https:// meili.XXX.cn/indexes/movies/documents' \
-H 'Authorization: Bearer masterKey' \
-H 'Content-Type: application/json' \
--data-binary @/www/movies.json
masterKey换成自己设置的MEILI_MASTER_KEY
✅ 成功后,访问 https:// meili.XXX.cn 可以看到 movies 索引和相关数据。
📍 第四步:配置并运行 docs-scraper 抓取 WordPress 网站内容
4.2 下载 docs-scraper 工具
终端中逐步输入以下命令
cd /www
mkdir docs-scraper
cd docs-scraper
git clone https://github.com/meilisearch/docs-scraper.git .
此处的git clone https://github.com/meilisearch/docs-scraper.git .命令格式不要错误了,后面会有一个点,这与不带点的有点区别,一个是直接下载目录中的文件到docs-scraper目录,另一个将整个目录都下载到docs-scraper目录,目录就会变成/www/docs-scraper/docs-scraper/,后面的命令就对不上了。
4.4 创建配置文件 config.json
新建一个config.json文件放到 /www/docs-scraper/ 目录下
粘贴以下内容(根据你的网站结构定制):
{
"index_uid": "xxx_docs",
"start_urls": [
"https://www.xxx.cn/"
],
"sitemap_urls": [
"https://www.xxx.cn/post-sitemap.xml"
],
"stop_urls": [],
"selectors": {
"lvl0": {
"selector": ".entry-header h1",
"global": true,
"default_value": "软件"
},
"lvl1": ".liu-app-version",
"lvl2": ".liu-app-des",
"lvl3": ".liu-app-img img",
"text": ".entry-content p"
},
"meilisearch_url": "https://meili.xxx.cn",
"meilisearch_api_key": "yourmasterkey"
}
4.5 执行抓取任务
在终端使用 Docker来启动
docker run -t --rm \
-e MEILISEARCH_HOST_URL=https://meili.xxx.cn \
-e MEILISEARCH_API_KEY=YourMasterKey \
-v /www/docs-scraper/config.json:/docs-scraper/config.json \
getmeili/docs-scraper:latest pipenv run ./docs_scraper config.json
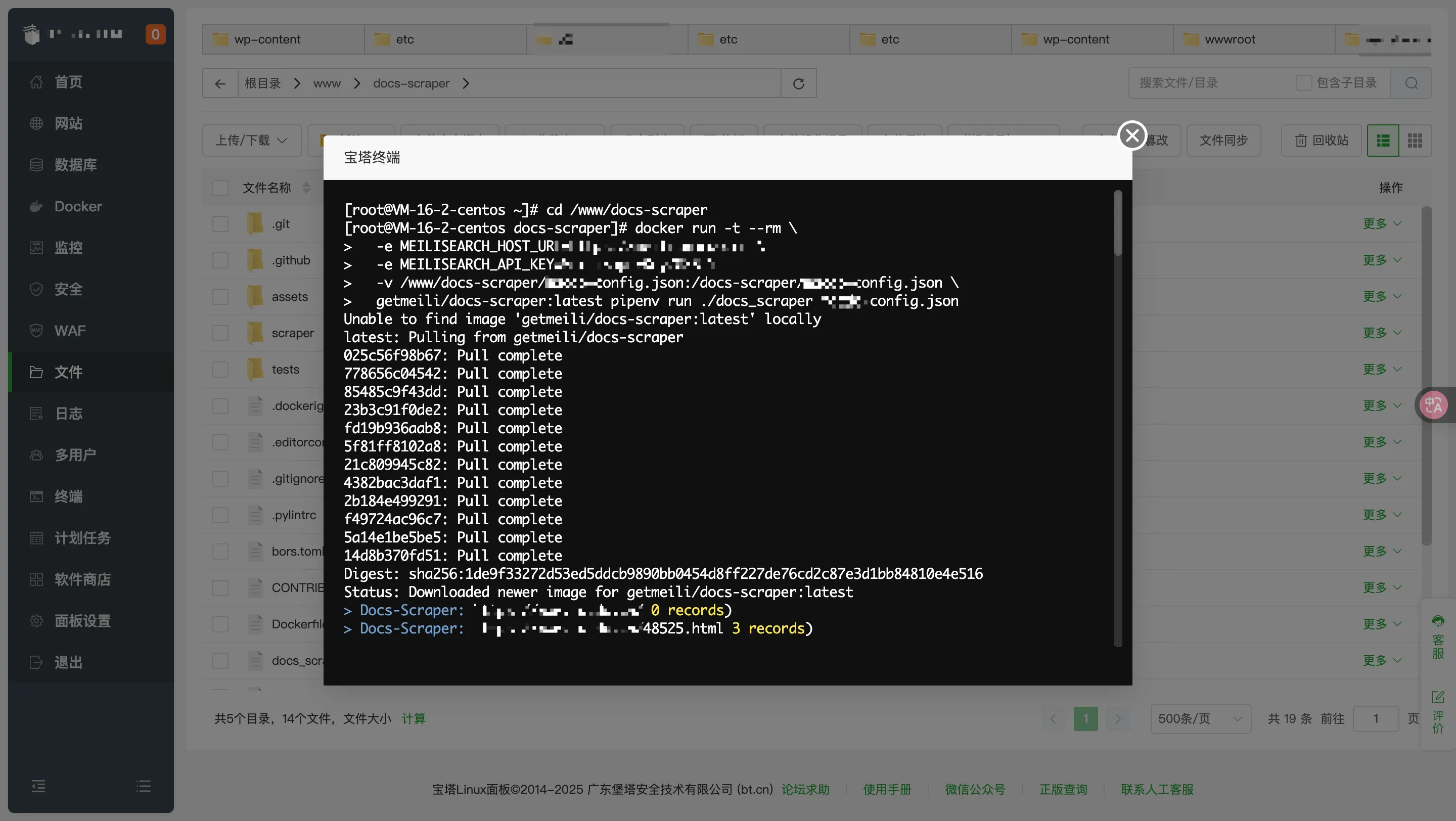
✅ 到这里,你的网站数据已经全部进入了 Meilisearch,接下来只需要集成前端搜索栏,就可以实现实时、模糊、秒级响应的超强搜索体验!
📍 前端集成步骤(使用 meilisearch-docsearch CDN 版)
✅ 1. 添加容器
在你希望显示搜索栏的位置,插入:
<div id="docsearch"></div>
✅ 2. 引入 meilisearch-docsearch 脚本
将脚本放在网站的footer处
<script src="https://unpkg.com/meilisearch-docsearch@latest/dist/index.global.js"></script>
<script>
const { docsearch } = window.__docsearch_meilisearch__;
docsearch({
container: "#docsearch",
host: "https://meili.xxx.cn",
apiKey: "你的masterKey",
indexUid: "xxx_docs"
});
</script>
✅ 3. 引入官方样式
确保页面中有引入 CSS 样式,否则样式会错乱:
<link
rel="stylesheet"
href="https://unpkg.com/meilisearch-docsearch@latest/dist/index.css"
/>
📢 注意事项
- host 必须写你的 Meilisearch 地址(比如 https://meili.xxxx.cn)。
- apiKey 目前是 Master Key,但线上正式使用建议生成一个只读 Search Key以保证安全!
- indexUid 必须和你抓取的索引名一致,比如 xxx_docs。
✅ 这样你的 WordPress 网站就可以通过 现代化前端组件 meilisearch-docsearch 实现极速搜索了!